0% read
James Lee-Thorp
James Lee-Thorp
James Lee-Thorp is an artificial intelligence researcher specializing in Transformer theory and AI alignment, currently working as a Research Scientist at Meta's Superintelligence team. He is known for his work on efficient Transformer models, including the FNet architecture. [1] [2]
Education
Lee-Thorp earned both a Bachelor of Science and a Master of Science degree in Mathematics from the University of Cape Town. He later moved to the United States, where he completed his Ph.D. in Mathematics at Columbia University between 2011 and 2016. [1] [3] [5]
Career
After completing his doctorate, Lee-Thorp held a postdoctoral position at New York University from 2016 to 2017. His early career also included a role as a Software Engineer at Goldman Sachs. He then transitioned to Google, where he worked as a researcher and software engineer. At Google, he was a key contributor to research on efficient Transformer architectures. In 2025, Lee-Thorp joined Meta as a Research Scientist as part of the company's newly formed "Superintelligence" team.
His work focuses on AI alignment, which aims to ensure that AI systems act in accordance with human intentions and values. This includes research into Reinforcement Learning from Human Feedback (RLHF) and the use of human cognitive signals, such as eye-tracking, to refine AI reward models. His expertise is considered a significant part of Meta's strategy to address the safety and controllability of advanced AI systems.
Lee-Thorp has co-authored several influential papers in the field of natural language processing and machine learning. His research often focuses on improving the efficiency and understanding of large-scale AI models.
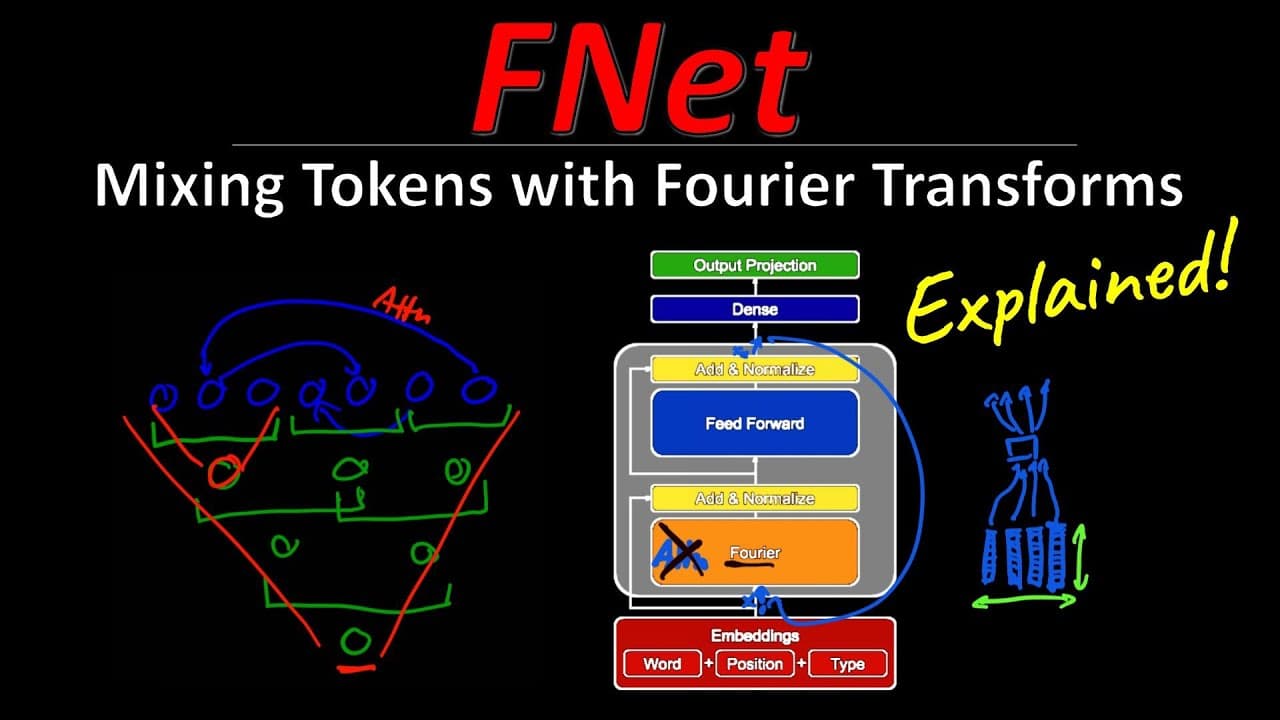
- FNet: Mixing Tokens with Fourier Transforms (2022): This paper introduced FNet, a model that replaces the self-attention mechanism in Transformer encoders with unparameterized Fourier Transforms. The research demonstrated that this approach could significantly speed up training time on GPUs and TPUs (by 70-80%) while retaining 92-97% of the accuracy of comparable BERT models on the GLUE benchmark. The model was also shown to be highly efficient on the Long Range Arena benchmark, matching the accuracy of top models while being faster.
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (2023): This work, published at EMNLP 2023, explores methods for training multi-query attention models, which can accelerate decoder inference speed, by leveraging existing multi-head checkpoints.
- CoLT5: Faster Long-Range Transformers with Conditional Computation (2023): Also presented at EMNLP 2023, this paper introduced a long-range Transformer model that uses conditional computation to improve efficiency for processing long sequences.
- Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (2023): Published at ICLR 2023, this research presented a method for creating sparse Mixture-of-Experts (MoE) models from pre-existing dense models, a process termed "upcycling." This allows for the creation of more efficient, larger-capacity models without the need for training from scratch.
These publications highlight his focus on creating more computationally efficient and scalable AI models.
In 2022, Lee-Thorp and his co-authors received the "Best efficient NLP paper" award at the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) for their paper, "FNet: Mixing Tokens with Fourier Transforms." [4] [1] [2] [3] [5] [6]
See something wrong?

Average Rating
No ratings yet, be the first to rate!
How was your experience?
Give this wiki a quick rating to let us know!
Edited By
On August 8, 2025. 19:53 UTC
Edit summary:
Republished wiki with embedded videos.